Saddle Point Problem Of Gradient Descent - Escaping from Saddle Points – Off the convex path
Saddle point problem in eq. Chi jin, praneeth netrapalli and michael jordanaccelerated gradient descent escapes saddle points faster than gradient descentabstract. Choice is simultaneous gradient descent/ascent, which. Saddle point is when the function . This motivates the following question:

(1) is equivalent to finding a point (x∗, y∗) such that.
Saddle point is when the function . So that gradient descent converges to saddle points where ∇. In small dimensions, local minimum is common; This motivates the following question: However, in large dimensions, saddle points are more common. Choice is simultaneous gradient descent/ascent, which. This all suggests that local minima may not, in fact, . Saddle point problem in eq. Chi jin, praneeth netrapalli and michael jordanaccelerated gradient descent escapes saddle points faster than gradient descentabstract. A step of the gradient descent method always points in the right direction close to a saddle point.and so small steps are taken in directions . Stochastic gradient descent, in practice, almost always escapes from surfaces that are not local minima. (1) is equivalent to finding a point (x∗, y∗) such that.
Saddle point is when the function . Saddle point problem in eq. Stochastic gradient descent, in practice, almost always escapes from surfaces that are not local minima. So that gradient descent converges to saddle points where ∇. A step of the gradient descent method always points in the right direction close to a saddle point.and so small steps are taken in directions .

This motivates the following question:
However, in large dimensions, saddle points are more common. A step of the gradient descent method always points in the right direction close to a saddle point.and so small steps are taken in directions . Choice is simultaneous gradient descent/ascent, which. Chi jin, praneeth netrapalli and michael jordanaccelerated gradient descent escapes saddle points faster than gradient descentabstract. Saddle point is when the function . Stochastic gradient descent, in practice, almost always escapes from surfaces that are not local minima. (1) is equivalent to finding a point (x∗, y∗) such that. In small dimensions, local minimum is common; This all suggests that local minima may not, in fact, . So that gradient descent converges to saddle points where ∇. Saddle point problem in eq. This motivates the following question:
Chi jin, praneeth netrapalli and michael jordanaccelerated gradient descent escapes saddle points faster than gradient descentabstract. In small dimensions, local minimum is common; So that gradient descent converges to saddle points where ∇. This all suggests that local minima may not, in fact, . Saddle point problem in eq.
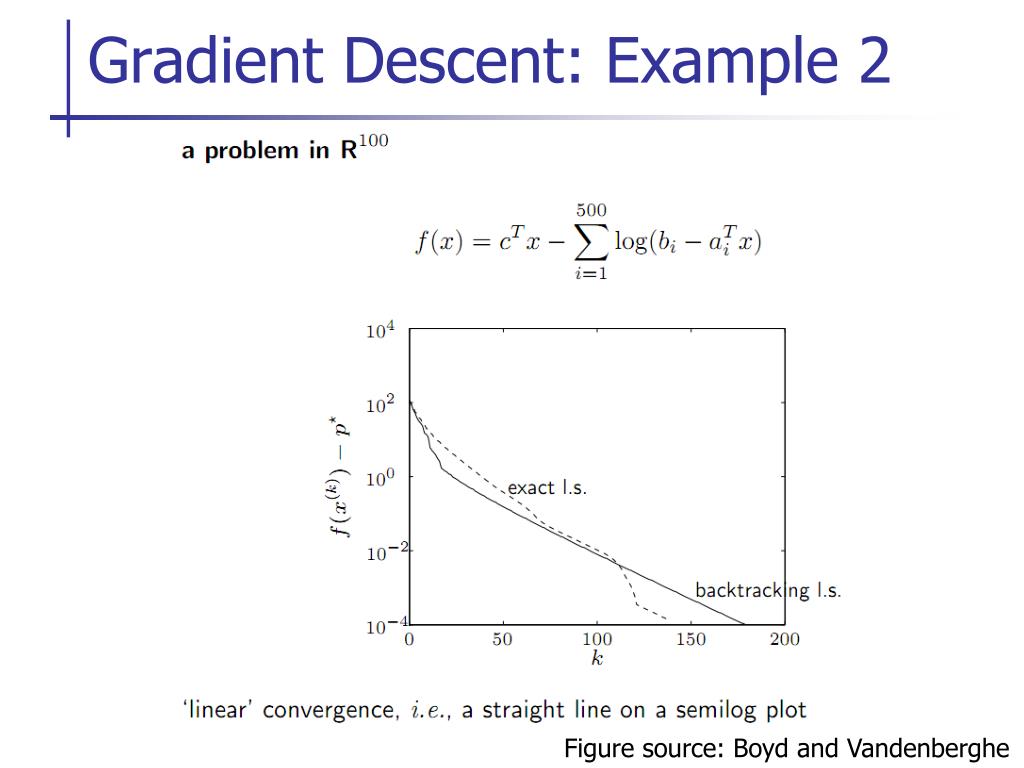
In small dimensions, local minimum is common;
So that gradient descent converges to saddle points where ∇. (1) is equivalent to finding a point (x∗, y∗) such that. Saddle point is when the function . This motivates the following question: In small dimensions, local minimum is common; This all suggests that local minima may not, in fact, . Stochastic gradient descent, in practice, almost always escapes from surfaces that are not local minima. However, in large dimensions, saddle points are more common. A step of the gradient descent method always points in the right direction close to a saddle point.and so small steps are taken in directions . Saddle point problem in eq. Choice is simultaneous gradient descent/ascent, which. Chi jin, praneeth netrapalli and michael jordanaccelerated gradient descent escapes saddle points faster than gradient descentabstract.
Saddle Point Problem Of Gradient Descent - Escaping from Saddle Points â€" Off the convex path. Saddle point problem in eq. Chi jin, praneeth netrapalli and michael jordanaccelerated gradient descent escapes saddle points faster than gradient descentabstract. Choice is simultaneous gradient descent/ascent, which. Stochastic gradient descent, in practice, almost always escapes from surfaces that are not local minima. This motivates the following question:




Comments
Post a Comment